The Snake that Knew Where the Food Was (and How to Dodge Obstacles!)

Imagine a snake that's not just about surviving—it’s got goals. It’s not just aimlessly slithering around the screen looking for food, no. This snake knows where the food is, and it’s determined to get there. It’s got a plan. It dodges obstacles like a pro, stays cool under pressure, and munches away on that food like it’s been doing this for years.
The Struggle Is Real: Learning at a Snail’s Pace
Now, here's the twist: the learning wasn’t fast. Not by a long shot. This snake didn’t wake up one day and suddenly become an obstacle-dodging food-finding expert. Oh no. It was a slow, painful process. Imagine trying to learn how to ride a bike but every time you fell off, you had to start from scratch (and there were lots of falls). That’s what happened here—every wrong turn, every collision with a wall, every time it bit itself—those were valuable lessons, just learned a bit... slowly. The model was like the tortoise in a race with a tortoise who also forgot to check the map.
But Wait! It’s a Genius!
Even though it took its sweet time learning, this snake turned out to be really good at what it does. It didn’t just learn to avoid obstacles like a confused worm slithering away from danger. No, no. It got to the point where it was predicting where the food would be and started making moves like a GPS system designed by an all-knowing snake god.
How? Well, it figured out the best route to food while avoiding every single obstacle. It didn’t just follow the closest path, like a kid at a candy store picking up every piece of candy it saw. It was strategic. It understood that sometimes, the straight line to food wasn’t the best path. Sometimes, it had to veer off, dodge that moving wall, and take a detour to avoid crashing into its own tail. A detour?! Yes, you heard that right. It learned that a little extra travel was sometimes worth it to stay alive and get food.
So, Why the Slow Learning?
The learning process was slow because the snake had to explore, trial, and error its way through the environment, constantly trying to optimize its strategy. It wasn’t like a lightbulb turning on instantly. Imagine a snake going through thousands of different scenarios where it kept messing up, failing miserably, and getting frustrated—no food, no survival, just sad, lonely snake thoughts. But the thing is, every time it failed, it learned something new. And the slow progress was actually a blessing in disguise. It gave the model time to refine its strategy, adding layers of wisdom to its slithering ways. Eventually, this methodical learning paid off big time!
Take a look at the image next to this section. It tells the story of our snake’s journey in graphical form. The first significant peak in the score can be seen around the 40th game, where the snake had a breakthrough moment and started to piece together some basic survival tactics. However, this early success was not stable—subsequent games were a mix of ups and downs.
The next noticeable high scores appear around the 80th and 100th games, showing that the snake was starting to grasp more complex strategies. But just as it was getting comfortable, there was a sudden drop in performance. This dip highlights how the learning process isn’t linear; sometimes, the snake took steps backward, struggling to integrate new information with what it already knew.
What’s remarkable, though, is how the model performed outstandingly around the 120th game. Right before this peak, it experienced its lowest score yet, a humbling reminder of how failure often precedes great success. This last phase was the turning point where the snake finally “got it” and executed its strategies with finesse, dodging obstacles and finding food like a seasoned pro.
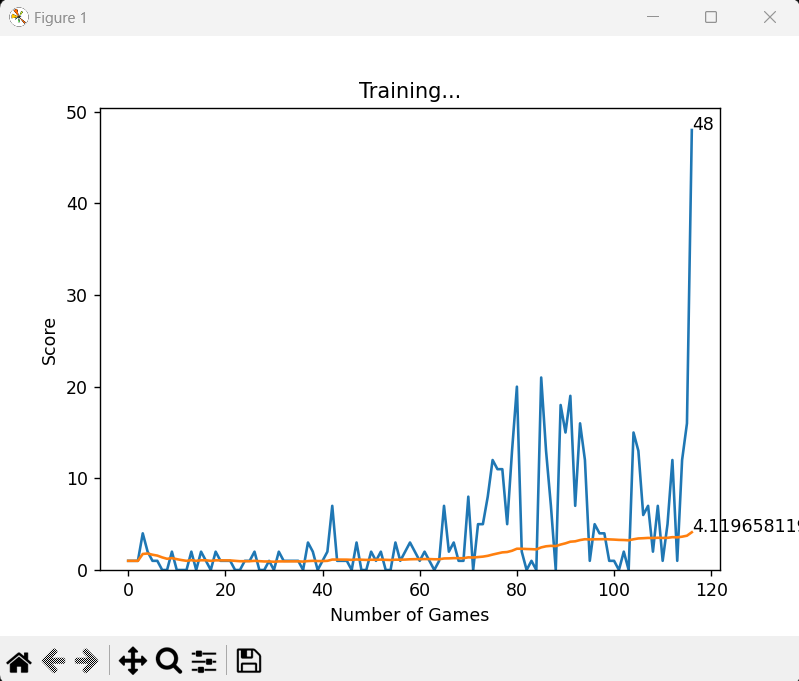
The Mystery of Peaks After Poor Performance
One interesting pattern that emerges in the learning journey is that high scores often follow periods of poor performance. Why is that? It’s all about the model's exploration and learning process:
- Exploration of New Strategies: After a series of poor performances, the model tends to explore new strategies as it tries to adapt and improve. These exploratory moves can seem risky or unconventional, but they sometimes lead to breakthroughs and higher scores.
- Learning from Mistakes: The low scores represent moments where the model faced situations it couldn't handle well. These moments provide valuable feedback that helps the model adjust its policies and improve its responses in similar future situations.
- Sudden Realizations: Reinforcement learning is rarely linear. The model might make sudden connections or learn more effective strategies after repeated trial and error, resulting in a significant jump in performance after a period of struggle.
In the snake model, the peaks following poor performances highlight the nature of reinforcement learning—success often comes after a series of setbacks. It's a testament to the model’s resilience, learning from mistakes, and its capacity for dramatic improvement after what seems like failure.
From Failure to Fame: The Model that Wins the Game
By the end of it, this snake had become the Picasso of obstacle avoidance. It could zig-zag, loop, and turn with precision—like a snake that had been practicing yoga for years. It was no longer just moving randomly around the grid; it was a focused predator hunting for food, avoiding everything from walls to its own growing body like it had a PhD in survival.
And there you have it. It wasn’t the fastest learner, but boy, did it become the best at what it did. This snake may have started off slow, but its patience, persistence, and the inevitable trial and error made it a true champion of the Snake world.
Find the related code on my GitHub repo.
Curious About What's Next?
We've come a long way with our snake learning to find food and dodge stationary obstacles like a true strategist. But what if the game became even more dynamic? What if those obstacles started moving? Would our snake be up to the challenge, or would it have to level up its game entirely to keep up?
In Part 2, we explore this next step: moving obstacles. These aren't just passive blocks in the snake’s way; they're active, unpredictable elements that force the snake to adapt and react in real time. Can our model handle this new twist, or will it get caught in the chaos?
