The Snake That Got Smarter (and Faster!)
After achieving a basic level of functionality in Part 1, I decided to escalate the complexity of the Snake AI in Part 2 by introducing a timer mechanism that added urgency to the agent’s decision-making. In this iteration, if the snake did not eat food within 6 seconds, the food would despawn and reappear at a new location. This penalized the agent for poor performance and required it to develop strategies for timely food consumption.
The Challenge: The Countdown
The new timer forces the model to not only survive but also make decisions rapidly. The agent needed to anticipate the food’s appearance, move toward it efficiently, and avoid obstacles—all within a strict time constraint. As you can imagine, this introduced new layers of complexity to the learning environment, requiring the agent to balance survival with speed.
The End Model: A Snake That Knows Where It's Going
By the end of Part 2, the Snake AI had undergone a significant transformation. Where it once struggled with direction and focus, it now confidently slithers towards its goals. While it still plays the game with precision, you might notice a fun quirk: it tends to veer towards the left more often than not! This isn’t just random; after the model finished training, the decision-making process has evolved in a way that makes the leftward movement almost instinctive—perhaps a result of the specific environment and training constraints. It’s not perfect, but it’s a fascinating behavior that showcases just how unique reinforcement learning can be in shaping the model's patterns.
The Slow Learner Syndrome
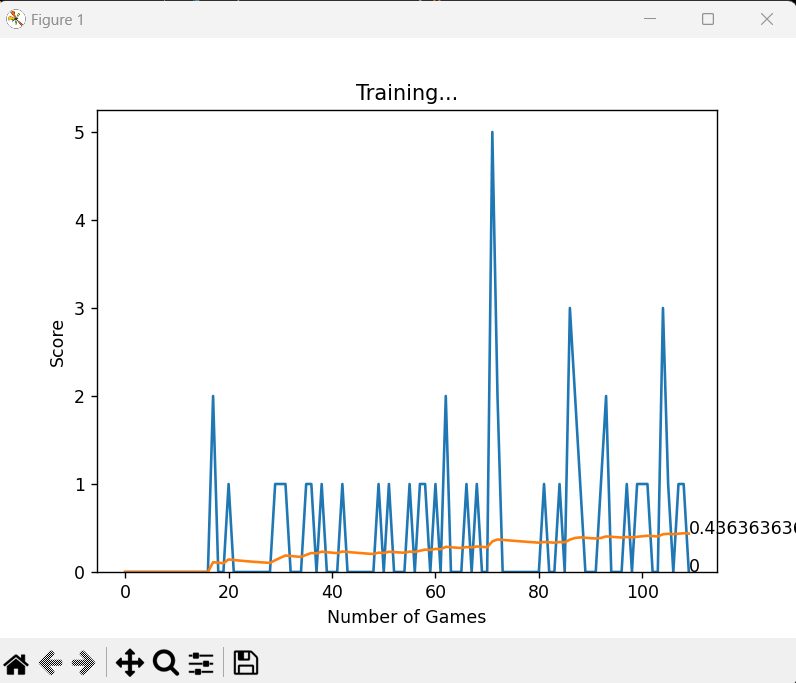
Initially, the agent struggled to learn effectively, despite being trained on hundreds of games. In the first 150+ iterations, the model showed no significant improvement in decision-making. It was slow to adapt, continuously making the same basic mistakes: failing to avoid obstacles, getting stuck in corners, and missing food. The model was too focused on random exploration, unable to generalize effectively from its experiences.
This is where I ran into the limitations of training from scratch. Reinforcement learning models, especially in complex environments like this, often require thousands or even millions of iterations to learn basic behaviors. The agent’s experience in learning was painfully slow and inefficient, especially when it lacked a foundational knowledge base.
The Problem with Training from Scratch
Training from scratch in reinforcement learning is notoriously slow, particularly when there are many variables involved. When starting from zero, the agent's exploration space is vast, and it lacks any prior knowledge about how to act in the environment. This leads to inefficient learning, where the agent needs to repeatedly encounter the same situations to "learn" even basic survival behavior.
At this point, I realized that the model needed a way to jumpstart its learning. Starting from scratch just wasn't effective enough, especially with the added complexity of time-based constraints. This is where the concept of transfer learning comes into play.
Rather than continuing with inefficient exploration, I decided to preload a pre-trained model—a classic Snake model that already understood basic behaviors like survival, avoiding collisions, and food consumption. This pretrained model provided a solid foundation, allowing the new model to skip the initial trial-and-error phase and focus on more advanced tasks, like adapting to the timer and avoiding dynamic obstacles.
Transfer Learning: A Technical Overview
Transfer learning is a technique where a pre-trained model, typically trained on a similar task or environment, is fine-tuned to solve a new, but related, problem. In this case, the pre-trained Snake model had learned to survive in a simple version of the game, without the added complexity of time constraints or moving obstacles. By leveraging this knowledge, the new model could focus on optimizing its behavior for the updated environment, significantly reducing training time.
The process works as follows: The pre-trained model provides a starting set of weights and biases based on its learning from the classic Snake game. These weights encapsulate the learned knowledge of basic survival strategies (such as navigating the screen and avoiding food collisions). When the new model is initialized, it starts with these pre-learned weights, which means it doesn't have to relearn basic survival tasks.
From there, the model is fine-tuned through further training in the new environment (with the countdown and moving obstacles). The agent takes the pre-trained weights and continues learning, adjusting those weights based on new experiences and the modified environment. This drastically reduces the number of training iterations required for the agent to achieve good performance, as it already has a solid base to build on.
How Transfer Learning Accelerated Performance
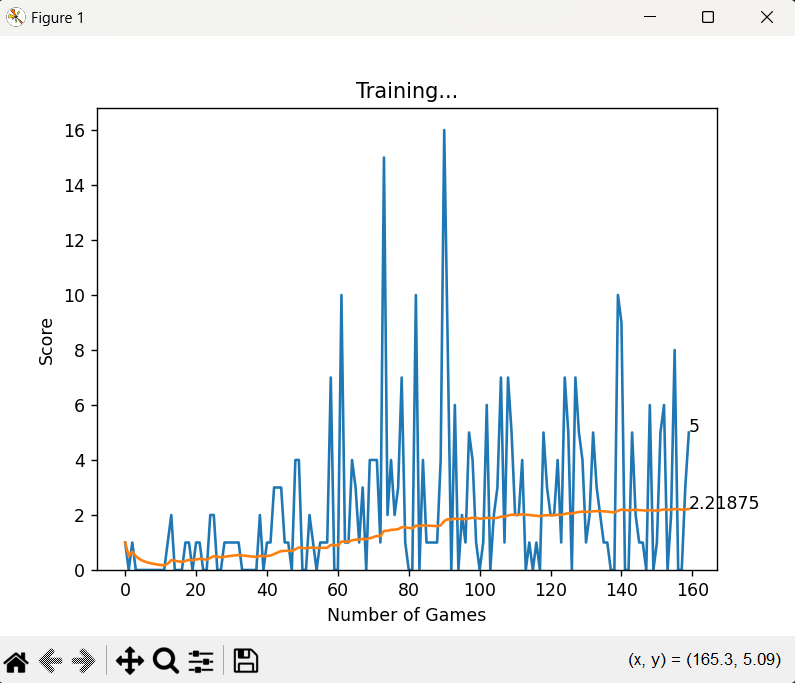
Once the pre-trained classic Snake model was loaded, the agent immediately began performing better. The pre-loaded model had already learned essential survival skills like avoiding self-collisions and navigating around obstacles. With this foundational knowledge, the agent could more effectively focus on the new challenge of adapting to a dynamic environment with a food timer and moving obstacles. The learning curve was dramatically reduced, and the agent’s behavior became much more strategic.
By combining reinforcement learning with transfer learning, the agent was able to navigate the more complex version of Snake with far fewer iterations. The model didn’t need to relearn basic behaviors—it could skip ahead and concentrate on optimizing its decision-making for the new game mechanics.
In addition to its enhanced decision-making skills, the agent developed a fascinating behavior: when it sensed the food was dangerously close to obstacles, it would circle around in a safe spot, waiting for the food to despawn. This cautious strategy ensured the snake didn’t risk colliding with obstacles. Once the food respawned at a safer location, the agent would move in to claim it, displaying a high level of strategic thinking and risk management.
Why Training From Scratch Doesn't Scale
Training from scratch, especially with reinforcement learning in complex environments, is inefficient. Without any pre-existing knowledge, the agent has to explore and learn from every situation independently, which can take a prohibitively long time. The model ends up "reinventing the wheel" for each basic task, such as avoiding walls, collecting food, and surviving. In contrast, transfer learning allows for faster convergence by building on knowledge already acquired, making it a far more practical approach for real-world applications.
In this case, loading the pre-trained model helped the snake learn in minutes what would have otherwise taken hours or even days. By preloading the basic survival strategies, the agent could focus on more advanced tactics like avoiding moving obstacles, efficiently navigating towards food, and optimizing the path within a timed environment. This approach not only made the learning process more efficient but also resulted in a much more robust agent overall.
Results: A Smarter Snake
By the end of Part 2, the snake had gone from barely surviving to becoming a formidable player in the game. It could predict where food would spawn, avoid moving obstacles, and make strategic decisions to maximize its survival chances. The process of transfer learning had accelerated the model’s progress by giving it a solid foundation on which to build. It’s a powerful example of how leveraging prior knowledge can significantly reduce the time and effort required to solve complex problems.
Check out the full code for this journey on my GitHub repo.
What's Next? Can We Take It Even Further?
Our snake has come a long way, mastering the art of dodging stationary obstacles and chasing down food with strategic precision. But here's the thing: while it's doing great, it’s still a single player, and we all know that sometimes more brains are better than one.
In Part 3, we step things up with multi-agent architecture. Imagine the power of multiple snakes working together—or against each other—each with its own goals and strategies. The current model is good, but what if we could take it further? What if collaboration (or competition) between agents could lead to even more refined tactics, faster decision-making, and a whole new level of gameplay?
Get ready for the next evolution, where the game becomes not just about a single snake’s survival but about creating a dynamic environment where agents interact and adapt in real-time. The challenge is set: Can the system handle the complexity of multiple agents, and can they outsmart each other while still mastering the game?